
The Linked Jazz project has derived most of the social relationships in its dataset from the transcripts of oral histories given by jazz musicians. One question we began to ask some time ago is: what other jazz historical material in digital form would be a good source of additional relationship data? One answer to that question is digitized photographs, specifically those with good-quality metadata.
Tulane University has a rich collection of historical photographs of jazz musicians living and performing in New Orleans and around the world. The Hogan Jazz Archive Photography Collection and Ralston Crawford Collection of Jazz Photography are two such collections, and we received two tab-delimited text files from Tulane, exported from their CONTENTdm system.
Some numbers: in this set we have 1,787 images, at least 681 unique individuals, and more than 2,700 depictions. Depiction is the FOAF term that we later used as a predicate in our triples from this dataset. One group photograph might depict several individuals, and one individual might be depicted in several photographs. People depicted in the same photograph can be said to “know” each other in some way.
In this post, we’ll describe the process we used to first standardize and reconcile the photograph metadata, and then describe the photographs and the people and relationships depicted using RDF triples.

Search results from Tulane’s CONTENTdm system
Looking at some search results on the front-end of the CONTENTdm site, you’ll notice proper names in several of the fields. The subject field, though it contains a semi-colon separated list of headings that includes subject terms as well as names, looked like the best bet for later matching against the Virtual International Authority File, or VIAF — most names here have birth and death dates.
Clicking on one of these items brings us to the image page. Scrolling down, we see more metadata.
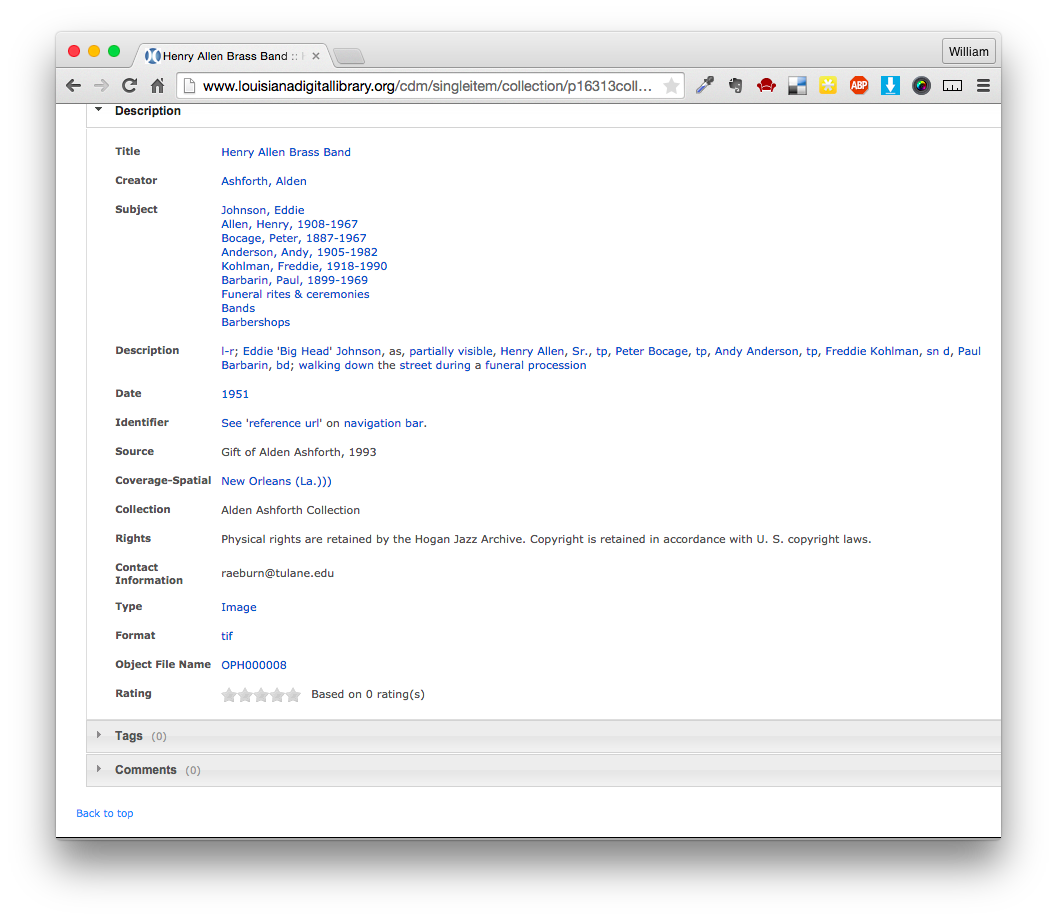
Metadata from a single photograph
Notice we also have date and location attributes here; that’s the case for many of these photographs, though not all.
Data Wrangling with Open Refine
We imported our tab-delimited files into Open Refine. We first split the Subject column on the semi-colon separator creating additional rows, each with just one subject term. We then used the fill down function to flesh out these new rows.
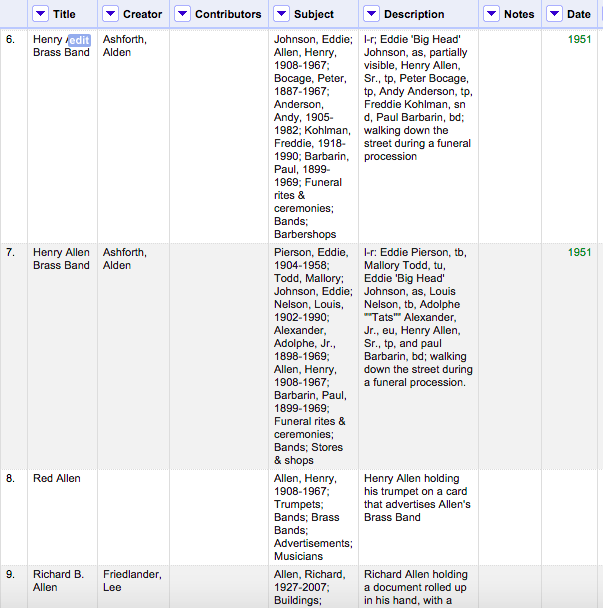
First, split the Subject column on the semi-colon
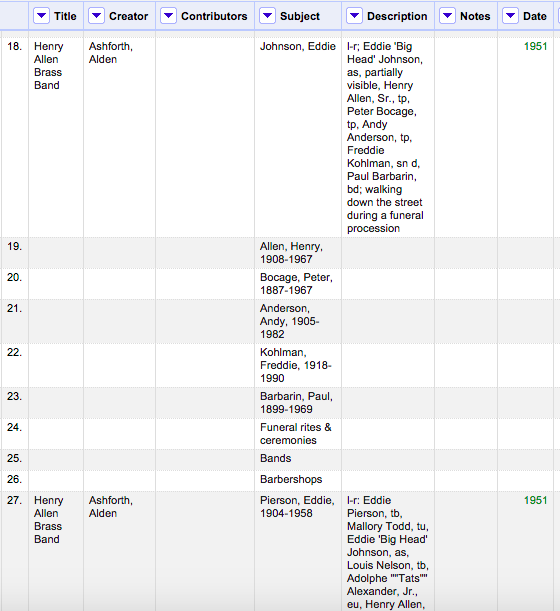
Result of the split, before using the Fill Down function
Since the proper names in the Subject column contain at least one comma, we filtered the data to display only those rows with a comma in the subject field. We then clustered and merged similar names to correct for any misspellings or misplaced commas.
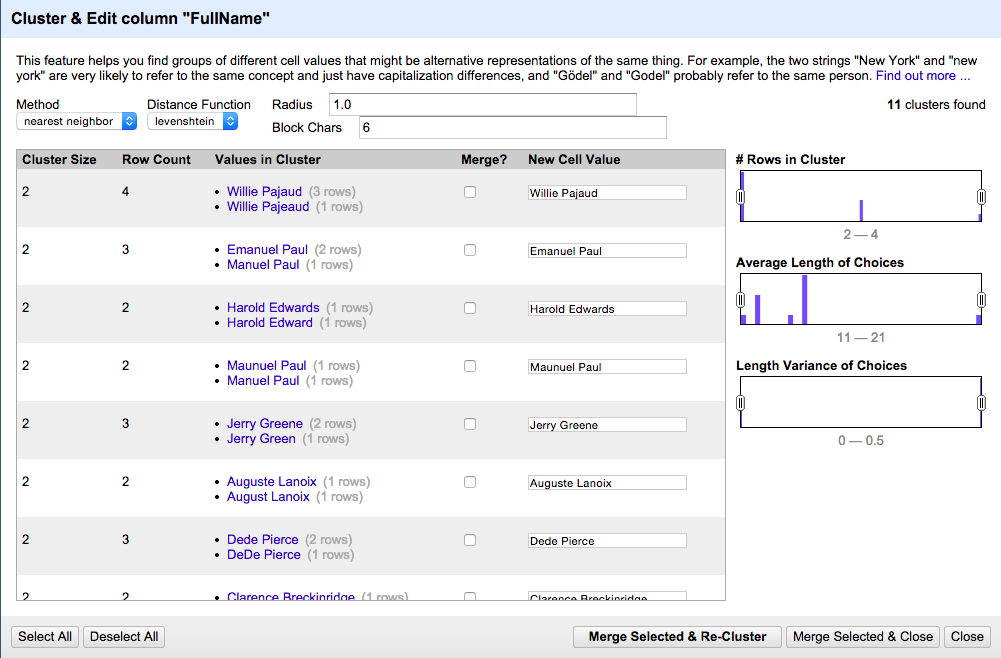
Cluster and merge name variants
Using the “Add column based on this column” function, we employed Google Refine Expression Language (or GREL) expressions to parse these names into new columns: full name, first name, last name, birth year, and death year. Specifically, we used the split, slice, reverse, and join string functions.
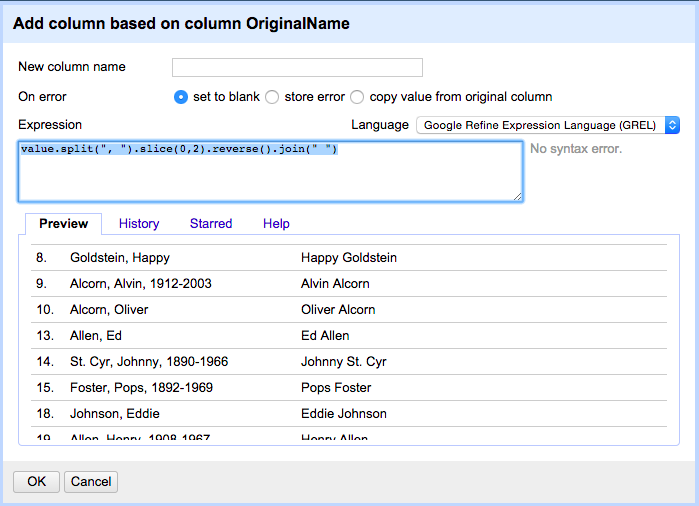
Parse the names and dates out into separate columns
With the name data formatted this way, we were able to begin matching the Tulane names to names in the Virtual International Authority File (VIAF) in order to get URIs for people in our dataset.
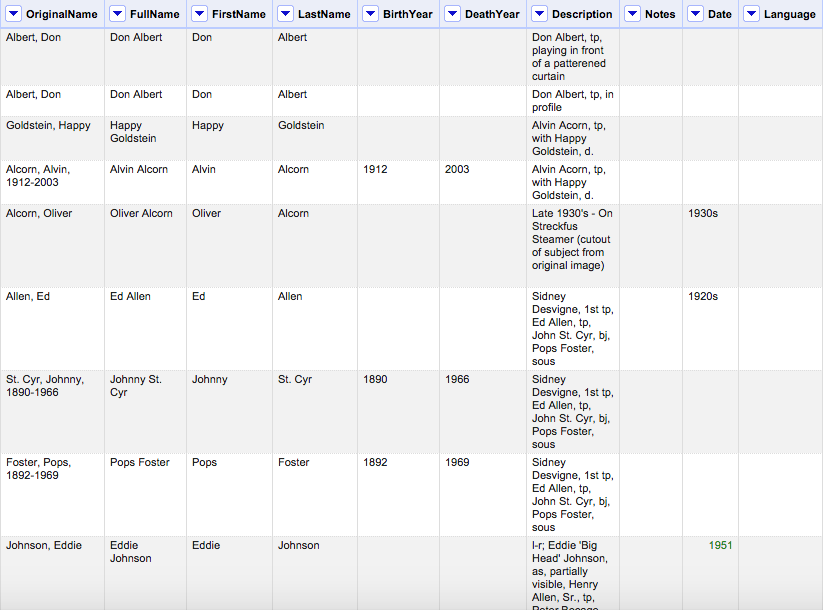
Names are now ready to be reconciled
Reconciling Names with VIAF
Our resident professional programmer Matt Miller wrote a Python script to search each name through the VIAF API, parse the XML results, and output to a JSON file. This includes authorized name, alternative names, birth and death dates, LC and Wikipedia identifiers, and titles of attributed works.
The script assigns quality “grades” to each result according to our confidence in its accuracy. For example, if a search of a proper name with birth year results in a single match, that is graded a high-quality match. If a proper name without a birth year yields a single match, that’s graded “medium.” If the name search resulted in more than one hit, that is a low-quality match.
In an attempt to refine our low-quality matches, we compiled a short whitelist of terms relevant to the collection, so that if “New Orleans,” “ragtime,” “jazz,” or “big band,” for example, appears in the title of a work, that result is bumped up to a “high” grade.

An example of a high-quality match from VIAF. Note the “titles” list, which we used to determine probable matches from searches with several results.
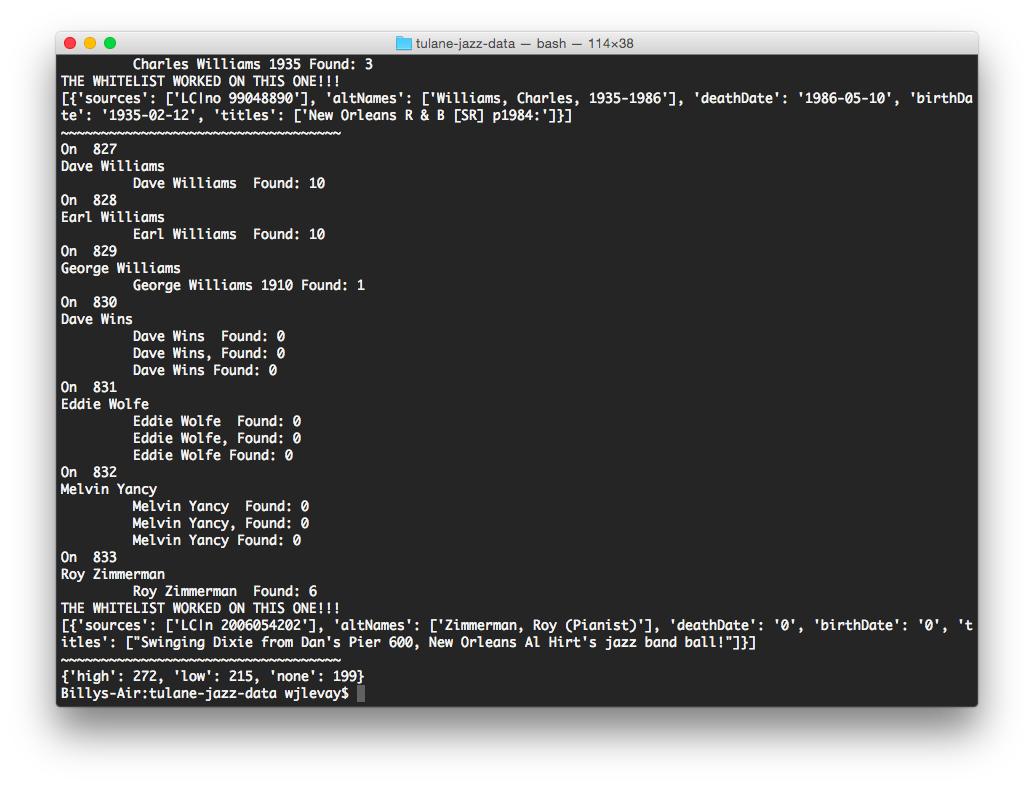
Notice that our whitelist was successful for Charles Williams and Roy Zimmerman.
Many of the approximately 680 unique names are local New Orleans musicians or otherwise minor jazz players, so we weren’t too surprised that our VIAF-search script yielded just 272 high-quality matches.
For some reason the script failed to provide Wikipedia or LC authority IDs for some key players, including Lil Hardin Armstrong, Johnny St. Cyr, and Jelly Roll Morton, so these IDs were added manually. Now that we had sources for our name URIs, we could start to construct our RDF triples.
Building N-Triples
Here we used another Python script, again with Matt Miller’s help, to build our N-Triples.
For our person URIs, if our VIAF results contained a Wikipedia ID, we used a DBpedia URI. If there was no Wiki ID, but there was an LC ID, we used the LC URI.
For our dates, we appended datatype IRIs, or internationalized resource identifiers, to specify the format of the date. (More on dates below.)
Many photographs in the collection have a value for the field “Coverage-Spatial.” We used GeoNames URIs to represent some of the most common cities in the dataset, including New Orleans, New York, Chicago, and Paris.
Dates
In constructing RDF Triples with these date values, we decided to use the Dublin Core term “created,” as our predicate and to append datatype IRIs to these literal triples.
Many, but not all, photographs in the collection have a “created” date; of these, many are expressed in one of three W3CDTF-compliant formats
There are, however, other date expressions, such as “1960s,” “circa 1950,” “Early 1949,” and “Spring 1946.”
| YYYY | http://www.w3.org/2001/XMLSchema#gYear |
| YYYY-MM | http://www.w3.org/2001/XMLSchema#gYearMonth |
| YYYY-MM-DD | http://www.w3.org/2001/XMLSchema#date |
| 1960s, circa 1950, Early 1949, Spring 1946, etc. | http://www.w3.org/2001/XMLSchema#string |
As you can see here, dates in W3CDTF format would be appended with an appropriate IRI, and dates not conforming to that format get the default IRI of “string.”
Types of Triples
We created six different types of triples, represented by these models:
- <personURI> <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> <http://xmlns.com/foaf/0.1/Person>
the subject URI represents a person - <personURI> <http://xmlns.com/foaf/0.1/name> “First Last”@en
the subject URI has the name “First Last” - <personURI> <http://xmlns.com/foaf/0.1/depiction> <photoURI>
the subject URI is depicted in the object URI, the photo - <person1URI> <http://xmlns.com/foaf/0.1/knows> <person2URI>
Person 1 knows Person 2 (by dint of being depicted in the same photograph) - <photoURI> <http://purl.org/dc/terms/created>
”YYYY-MM-DD”^^<http://www.w3.org/2001/XMLSchema#date>
the photo was created on this date, which appears in a format defined by the W3C XML Schema - <photoURI> <http://purl.org/dc/terms/spatial> <geonamesURI>
the photo has a spatial coverage of the place represented by the object URI
We have more than 4,200 triples from this dataset. And using the D3 Javascript library, we created a preliminary network graph with person nodes connected via photo nodes.
Future Work
Some other areas we’d like to focus on in addition to fleshing out the network graph are:
- Integrating this data with the existing Linked Jazz dataset.
- Improving the VIAF searching script and refining more of our low-quality matches.
- Automate the process of looking up placename URIs in the GeoNames dataset.
- Work with Tulane to publish this linked data.
- Account for the existence of photo collages in this set. We should not be asserting any personal connections among individuals who happen appear in the same collage.