
As linked data technology has developed over the last several years, the Linked Jazz project has continued to experiment — most recently interlinking our core jazz name entity list, derived from oral histories, with other jazz archival materials and their related metadata. Our research benefits from many ongoing collaborations, including that with Jeff Rubin and The Hogan Jazz Archive at Tulane University (our work identifying jazz relationships through historical photographs from Tulane University archives has been described here by William Levay), and with Gino Francesconi and Rob Hudson at the Carnegie Hall Archives. This post details a pilot we conducted to identify jazz musicians in both the Linked Jazz network and a subset of the Carnegie Hall Performance History Database focusing on jazz events from 1912-1955. From these entity matches, we created a visualization of the shared relationships between the two datasets. This first step in data interlinking allowed us to explore the possibilities as well as the limitations of the data integration process, and to identify common problems and best practices when reviewed alongside related use cases.
An Interlinking Use Case
Carnegie Hall Data
The Carnegie Hall Archives maintain a database of performance history that holds information about the events at the performance spaces of Carnegie Hall since 1891. Starting in 2013, they began to publish the information online as the Performance History Search, allowing users to explore some 50,000 unique events encompassing roughly 90,000 people/performers — a significant contribution to researchers of music and cultural history. As part of the performance history database effort, Carnegie Hall Associate Archivist Rob Hudson worked to transform the historical performance history data into Linked Open Data [1].
This pilot study, undertaken by Hannah Sistrunk and Molly Reese-Lerner with the support of Matt Miller, focused on a well-curated subset of the full Carnegie Hall performance history data. Specifically, there were two data sources selected from ‘jazz’ genre (loosely defined) Carnegie Hall events from 1912 to May 1955:
- RDF triples describing 19197 people and their associated data (instrument played, birth/death date and location, profession)
- RDF triples describing 154 jazz events including performer and group names, date, place (e.g. main hall), and title (top of concert program)
Example of Ella Fitzgerald birthPlace triple from the Carnegie Hall person dataset:
<http://data.carnegiehall.org/names/Ella_Fitzgerald> <http://dbpedia.org/ontology/birthPlace> <http://sws.geonames.org/4776024>
Example of Event dateTime triple from the Carnegie Hall event dataset:
<http://data.carnegiehall.org/events/CH_19530424_2030><http://purl.org/dc/terms/date>"1953-04-24T20:30:00-05:00"^^<http://www.w3.org/2001/XMLSchema#dateTime> .
The event data was limited to ‘parent’ events. That is, many Carnegie Hall events are split into ‘sub-events,’ but for the purposes of this study we focused on the top-level event.
Linked Jazz Data
As other Linked Jazz posts and publications have described, our dataset is built on a collection of 50+ jazz oral history transcripts from which relationships between jazz musicians are derived. When the person being interviewed mentions another person, an RDF triple is generated to describe that ‘Person A knows of Person B’. We used two Linked Jazz datasets for this study [2]:
- RDF triples of the Linked Jazz name list that includes a sameAs connection between the Linked Jazz URI and a commonly-sourced URI (primarily DBpedia), as well as the foaf:name for each person.
- RDF triples of relationships between Linked Jazz people
Bringing It All Together
Using these four datasets, we wrote a series of Python scripts that identified the people that existed in both domains (more on this process below). In other words, we identified the people who both performed in Carnegie Hall and were mentioned or interviewed in a Linked Jazz foundational jazz oral history (total= 373). From this group of matches and the relationship data from each context, we produced a new dataset containing 1) Linked Jazz relationships where a person in both contexts ‘knows of’ someone else (total=3058); 2) Carnegie Hall relationships where two people who are in both datasets performed at the same event (total=6706); 3) A subset of relationships that fall into both of the first two categories (total=293).
The results were made available for exploration through an interactive Gephi visualization.
Matching Entities and Names
Interlinking of information that has already been converted to the RDF format is significantly more straightforward than integration in other formats, but interoperability and interlinking in any format rely on shared entity authorities to assure that linked entities are verifiably the same entity. Linked Jazz prioritizes DBpedia to reconcile the names in our network (although we are now exploring Wikidata, which did not exist when the Linked Jazz project began), and includes 1518 DBpedia URIs, or 76%, of the 2008 people entities in our dataset. The remaining URIs are sourced from the Library of Congress Name Authority File (182 URIs), MusicBrainz (73 URIs), AllMusic (14 URIs), and Linked Jazz minted URIs where entities could not be identified from existing authorities at the time of creation (222 URIs).
The RDF data provided by Carnegie Hall primarily used Carnegie Hall minted URIs for the thousands of people, events, and musical works; at the time of the RDF dataset creation, it was impractical to cobble together existing URIs for this large dataset that included many obscure people and works. However, there were a small number of DBpedia URIs (1449) that had been identified and added to the data. Matching DBpedia URIs in both datasets was a logical step to identify people in the Linked Jazz network who had also performed at Carnegie Hall. However, because not all people were identified with these URIs in the performance history data, we also relied on string matching of names between the datasets.
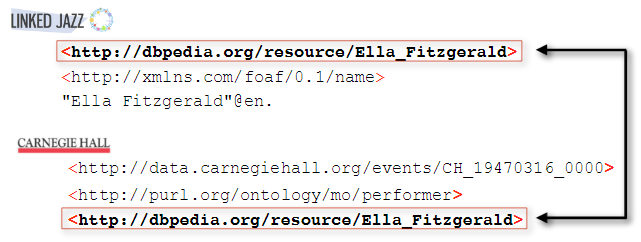
Matching people in both RDF datasets by their DBpedia URIs.
In past Linked Jazz research, including our work with Tulane University archival jazz photographs, we approached string matching by using OpenRefine and the Google Refine Expression Language (GREL) to parse names and match them to URIs from authorities such as Virtual International Authority File (VIAF). We have also used Elasticsearch with large datasets to find potential matches between string names and close variants. As Linked Jazz researcher Karen Hwang demonstrated in her post on Enriching the Linked Jazz Name List with Gender Information, once a URI is identified it is often possible to move between URI authority sources for data enrichment and entity matching using relationships provided by a specific authority. For example, DBpedia often specifies the corresponding identifiers for VIAF, LC/NAF, MusicBrainz, and others. String names reconciled to URIs can be matched to other well-established URI sets such as those used by Linked Jazz.
In this Linked Jazz-Carnegie Hall name string matching effort, we took a slightly different approach in matching names: we used a series of Python scripts with the Python Human Name Parser module to match foaf:name objects from each dataset.

An example of matching foaf:name string objects.
The module parsed each full foaf:name object into first name and last name separately, and then matched people with the same first AND the same last name. We employed this method to control for name variants such as “Bill Robinson” = “Bill Bojangles Robinson”, and “Benny Goodman” = “Benny Goodman and His Orchestra.”

Python Human Name Parser helped match names and control variation from nicknames and other differences.
This string matching method is a relatively conservative one, in that it does not account for small name spelling variations. On the other hand, for very common names that may occur for more than one person, we have no automated way to verify that the match is the same person without an authority record/URI.
- The Python Human Name Parser string matching method returned 264 matches.
- The URI matching method (using the RDFLib Python module) returned 268 matches.
- We combined the resulting matches from each method and deleted duplicates, resulting in 373 matches.
Interestingly two Linked Jazz minted URIs representing George Moore and Robert Harris were matched to Carnegie Hall performers during the string matching process. These individuals represent lesser known jazz musicians because no URI could be identified for them from DBpedia, LC/NAF, MusicBrainz, or AllMusic. The matches of LJ mints to Carnegie Hall performers (and therefore to specific events) indicate the power and potential of linked data interlinking to increase discovery and contextual enrichment of previously siloed data. This matching also points to a benefit of string matching methods, which in this case were still able to identify matches that would have been undiscoverable using only URI matches.
Identifying Common Relationships
With this relatively small set of people that were common to both contexts, we turned to exploring the common relationships between people in these contexts. The Linked Jazz network is built on the ‘knows of’ relationships described above that provide the structure for the Linked Jazz Network Visualization. Using a simple Python script, we isolated each of these ‘knows of’ relationships for each person among the 373 linked people. Similarly, we identified the relationships within Carnegie Hall for the 373 people. The Carnegie Hall relationships were defined by people who performed at the same event. We can’t say definitively that they ‘played together’ because of the sub-events and multiple works that could have been performed with various musicians through a single event. However, we can say that, based on the archival record, the two people were at Carnegie Hall on the same night performing in the same event.
Finally, we identified the common relationships between these two sets of relationships. Two people connected in this group played at the same Carnegie Hall event AND are linked by a mention in a jazz oral history interview. This kind of network relationship data necessitates some kind of visualization to explore the connections between people. Because of this, as noted, we created an interactive and searchable visualization using Gephi.
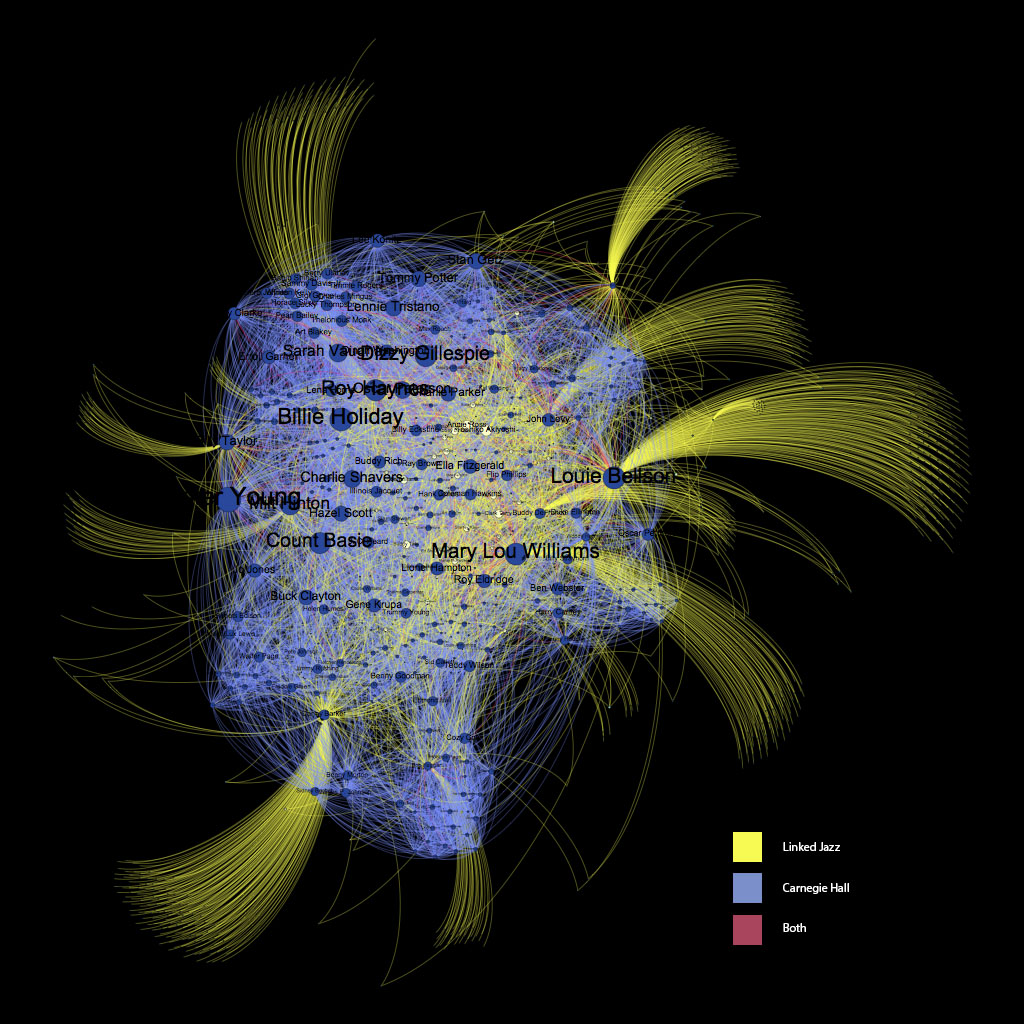
Static view of the Carnegie Hall and Linked Jazz relationship visualization.
Future Work
Rob Hudson and the Carnegie Hall team have continued to curate the performance history database and update the corresponding linked data triples. While this study was limited to jazz events from 1912-1955, more recent event and people data has since been generated. Moving beyond this basic interlinking pilot study, there are many research and data enrichment possibilities in working with this important historical performance information. For example, we could expand the Linked Jazz network by adding ‘knows of’ relationships for those people that performed in the same events at Carnegie Hall. Additionally, Linked Jazz person data could be enriched by information like birth/death year and place or instrument from the Carnegie Hall triples. The temporal information from event dates also has tremendous research potential in tracking the careers of jazz musicians when combined with the relationship network information from Linked Jazz.
As more libraries, archives, and museums publish data in the RDF format using common URIs, integration with external datasets will likely become simpler. However, string matching methods used to make connections with external data will continue to be an important part of integration work, and therefore warrant attention and testing to find the best method for particular contexts or types of data. Taken with other past and ongoing Linked Jazz use cases and research, we hope to identify common considerations and best practices in approaching data interlinking.
Python scripts for this study are available on GitHub.
1. Rob Hudson’s work converting the SQL database to RDF is described here and here. The scripts for linked data creation are available on GitHub.
2. The relationship and name authority data that Linked Jazz generates are available through a SPARQL endpoint or direct download.