
Inspired by Judy Chaikin’s “The Girls in the Band”, a documentary spotlighting the lesser-known history of women in jazz, Linked Jazz set out in 2014 to amplify the stories of jazz women by processing more interviews with female jazz musicians. A result of this activity was that the percentage of women in our list of people mentioned in interviews seemed to grow at a more rapid pace than previously. The list until then had been overwhelmingly men. We wondered: Could we preliminarily assume that jazz women mention other women in the context of their lives and careers more often than men in jazz mention women? This was more a tangential observation for us than a formal research area to pursue. But we realized adding such attributes to our list of names could enable new discoveries for users. Enriching our dataset of 2000+ names with gender information became Linked Jazz’s first attempt to create a data mash-up with other open sets of data that provide semantic definition.
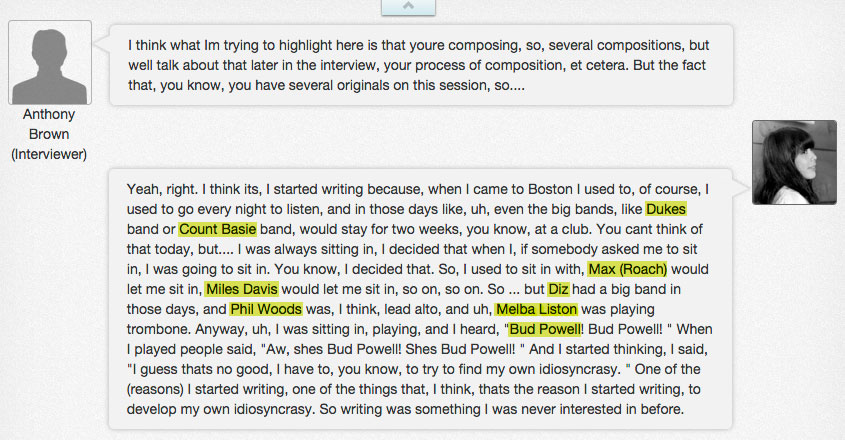
Excerpt from Anthony Brown’s interview with jazz pianist Toshiko Akiyoshi, 2006, with mentioned names
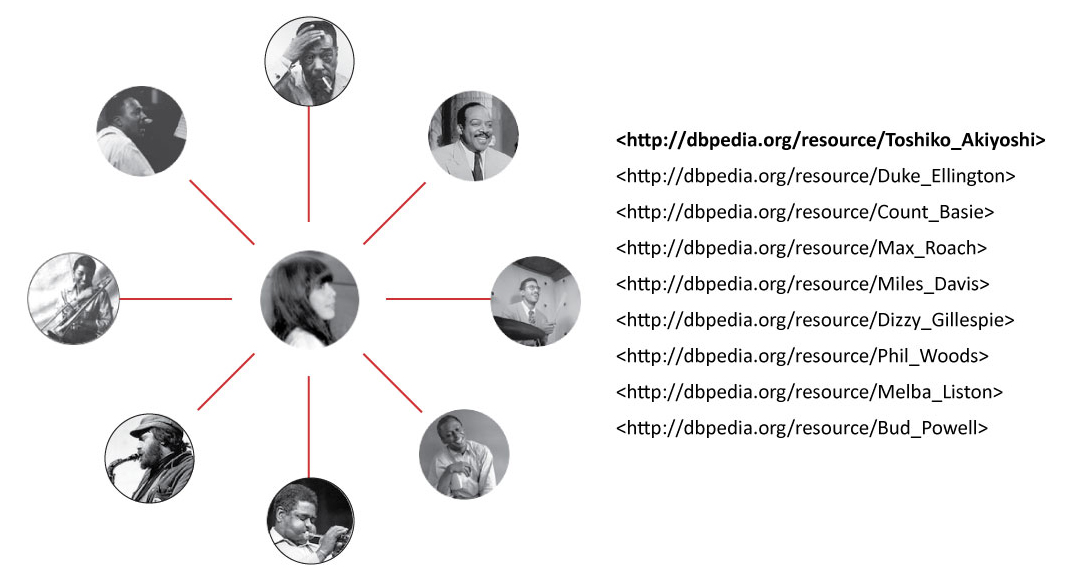
People mentioned in the passage reconciled as URIs
Linked Jazz uses three resources to reconcile name entities harvested from interview transcripts into valid URIs: 1) the DBpedia dataset, derived from the Wikipedia; 2) MusicBrainz, a Linked Open Data resource specializing in the music domain; and 3) the Library of Congress Name Authority File. Names that cannot be reconciled using any of these three resources but which produce valid citations through online search are minted as Linked Jazz entities in the linkedjazz resource namespace.
Examples of URIs in our list:
DBpedia URI for Clora Bryant
<http://dbpedia.org/resource/Clora_Bryant>
MusicBrainz URI for Little Miss Cornshucks
<http://musicbrainz.org/artist/480e178a-e940-4e6e-970c-a561bd7dcb9b>
LC/NAF URI for Mae Barnes
<http://id.loc.gov/authorities/names/n93053571>
Linked Jazz minted URI for Winnie Brown
<http://linkedjazz.org/resource/Winnie_Brown>
As our first step towards finding gender data, we exported this list of name entity URIs from our database into a static JSON file, representing the full curated list of name entities harvested from transcripts to date. 2006 URIs comprised this list. There were 15 that we removed from our test group due to processing errors, and 219 Linked Jazz mints which were also excluded from our mash-up test, since the linkedjazz URIs could not be used to query other resources. Our target group of names to enrich therefore became 1772.
Querying DBpedia
Linked Jazz prioritizes DBpedia to reconcile names, in part due to our original decision to pre-populate the name mapping tool for our transcript analyzer with DBpedia URIs for jazz artists.[1] With over 85% of our target list stemming from DBpedia (1519 URIs), DBpedia was the clear first choice to query gender data using its SPARQL endpoint. DBpedia records, however, contain no explicit gender property, but gender qualifications are sometimes found among the subjects applied to a person, called “categories” on Wikipedia.
In addition, DBpedia provides extensive sameAs references from other resources.
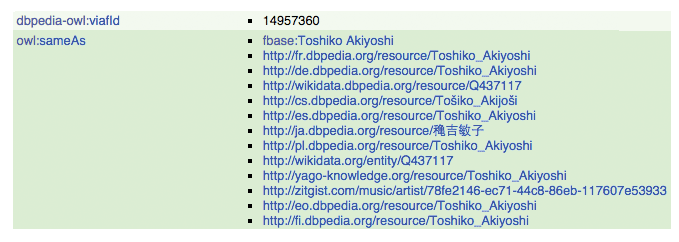
VIAF ID and sameAs references for Toshiko Akiyoshi on DBpedia
We wrote a Python script to loop through our JSON list of names to SPARQL query and store the following, if present, for any DBpedia URI in our list [2]:
- “dcterms:subject”: the entire list of subjects associated with the person;
- “db-pedia:lccn”: the unique reference identifier for the person in the Library of Congress Name Authority File;
- “db-pedia:viaf”: the unique reference identifier for the person’s cluster record on the Virtual International Authority File (VIAF);
- “owl:sameAs”, storing only matches with “http://zitgist.com”, whose trailing string is the person’s unique identifier on MusicBrainz.

Example of stored results from the DBpedia SPARQL query (Toshiko Akiyoshi)
The list of retrieved subjects for each person was then parsed for any gender-related information, using regular expressions to match “female”, “women”, “male”, and “men”. There was discussion whether additional, non-binary terms could be reliably applied; however, in spot-checking a sample group, none were found.
Less than 20% of our entire list could be enriched with gender information using this method, representing a 21.7% identification rate for our DBpedia URIs. A point of note was the distribution of identification. About 50% of those identified were women, which seemed far from representative of our list of names at a glance. Revisiting the subject data, we realized gender-qualifying terms are more often found for women than men in DBpedia’s subject terms, for example “Female jazz musicians” for a female jazz artist versus “Jazz musicians” for a male jazz artist. (A comparison with more current DBpedia data seems to indicate more equal application of gender qualifiers in the meantime.)
Querying MusicBrainz
From our DBpedia query, we were able to retrieve an additional 435 MusicBrainz IDs to add to the original 71, equaling 506. The decision was made to query all 506 artists— regardless of whether gender information had already been derived from DBpedia—for comparative purposes. Unlike DBpedia, artist records on MusicBrainz include a specific metadata element for gender. The Python module musicbrainzngs (“Next Generation Schema”) was used to loop through our list once again to collect gender information from MusicBrainz. 461 of the 506 held gender information, representing a 91.1% identification rate. And unlike DBpedia, the split of men to women within those identified was 88% to 12%.
Querying VIAF
VIAF maintains cluster records that are an aggregation of authority files from national libraries around the world, including the Library of Congress Name Authority File. Because of this, it was deemed unnecessary to query Library of Congress in addition to VIAF. VIAF can automatically resolve any Library of Congress identifier into the proper VIAF record by passing the Library of Congress identifier in a URL. For example, n82025133, the LC/NAF ID for jazz pianist Mary Lou Williams, when passed to VIAF as http://www.viaf.org/viaf/lccn/n82025133 resolves automatically to the VIAF cluster record http://viaf.org/viaf/105289239/. VIAF also makes the cluster record data available in structured XML when the VIAF record is requested with the trailing string “/viaf.xml”, for example, http://viaf.org/viaf/105289239/viaf.xml. Gender data can be found in the XML tree on VIAF under the element <ns2:fixed><ns2:gender>. Using a combination of these two VIAF handlers, we looped through all entities in our list that have either a VIAF id or LC/NAF id or both—most of which were obtained through our earlier DBpedia query—to automate requests for VIAF’s XML records. We then extracted the gender element from each record for storage in our list with the Python module xml.etree.ElementTree. 1390 VIAF entity calls were made and 1389 values were returned. This very high identification rate of 99.9% results from the fact that VIAF seems to require a value for this field. “u” for “unknown” is also an allowable value. Upon examination, the one missing result was due to an error on DBpedia in the given VIAF ID for that person.
Even when “unknown” is taken into account, the positive identification rate relative to the possible number was still very high: 81.8% (1137). Within this number, the breakdown between men and women was 89.4% and 10.6%, respectively. Because the gender field is explicit in the VIAF record, the Python script to query VIAF was conceived to pull in any value. No other values, however, were present besides the codes for female (‘a’), male (‘b’), and unknown (‘u’).
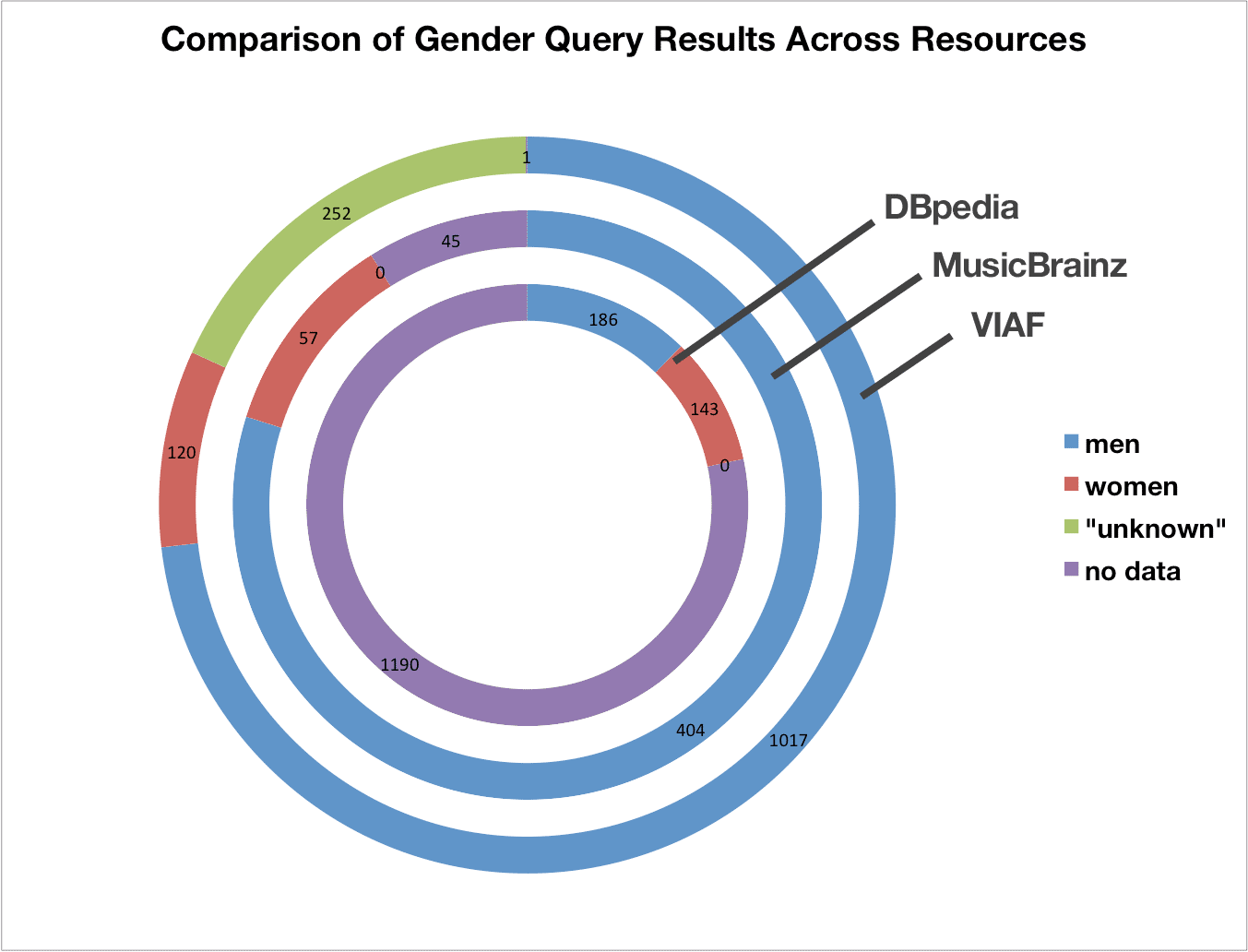
Gender data results showing the distribution of information retrieved based on the possible number of results. Each source was queried by a different number of names in our Linked Jazz list, dependent on the number of IDs we held for each resource.
Using these three methods, we were able to enrich 1329 people in our name list with gender data, representing 75% of our target list.
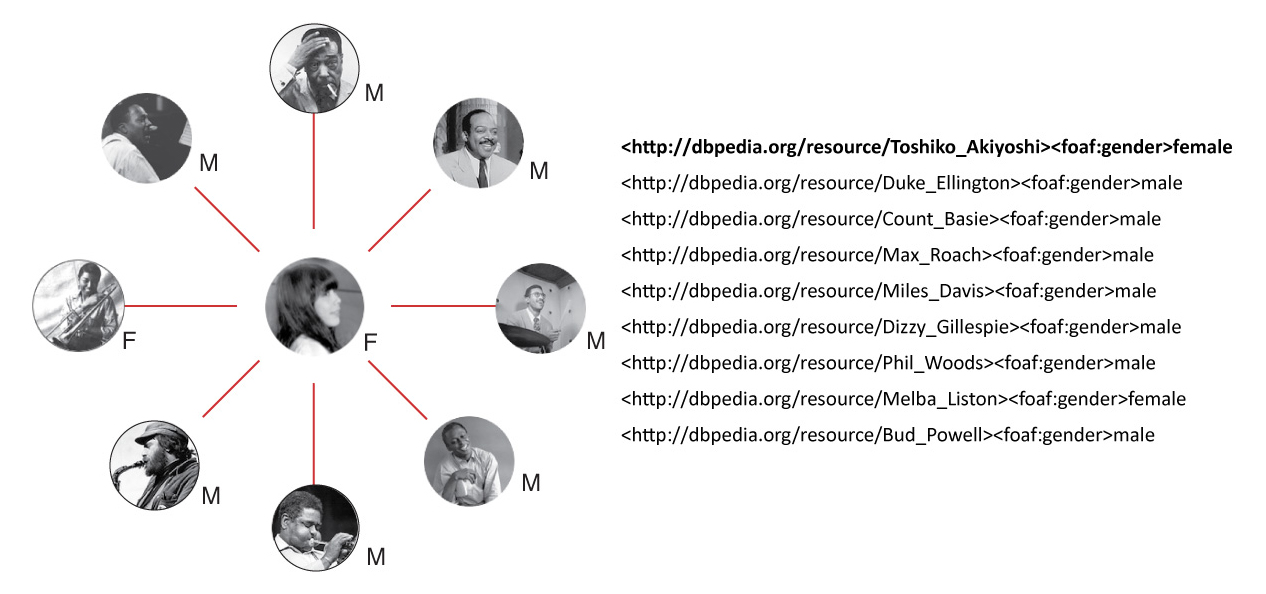
Visualized mashup of our transcript data with gender data from other resources
Future directions
Related work that Linked Jazz is exploring:
- Enriching our dataset of musicians with an instrument attribute;
- Developing tools that allow users to explore our interviews and interview data by attributes like gender and instrument;
- Collaborating with other institutions to facilitate mash-ups of our interview data with other datasets in the jazz domain, like discography and performance data.
1. More on this topic can be found in the article “Crafting Linked Open Data for Cultural Heritage: Mapping and Curation Tools for the Linked Jazz Project”.
2. Note that DBpedia may use different prefixes in more current versions of its dataset to define namespaces.